Profiling Programs on the Amiga
Sometimes you are curious where a program spent its time.
Then profiling can help. Since amigasshd delivers only 10kB/s upload speed an an A3000, i wanted to look into it.
Luckily the gcc compiler for the Amiga supports gprof, so all I need is to create the program with the correct options.
Create a program with gprof output.
Here are my release CFLAGS:
OUTDIR := Release
CFLAGS += -Os -fomit-frame-pointer -mregparm
LDFLAGS += $(STRIP)
And to create output for gprof I changed this into
OUTDIR := Profile
CFLAGS += -Os -mregparm -pg
Notice that -fomit-frame-pointer can't be used together with profiling information.
Now running the program yields a file named gmon.out.
Evaluating the programs output.
I used a 1MB file and copied it via
scp -P 2222 1MB.log A3000:Ram:x
and got an upload rate which were even worse (6-7kB/s), which is explained by the overhead added to each function. Once the upload finished and the program finished, I copied the file gmon.out back into the same folder where the created program resides. Now chdir into that folder and run m68k-amigaos-gprof amigasshd and you'll get lots of output.
Isn't there a more convenient way to somehow read the data? Yes, get some tools:
pip install gprof2dot
sudo dnf install graphviz
And now run:
m68k-amigaos-gprof amigasshd | gprof2dot | dot -Tpng amigasshd-a3000.png
to get
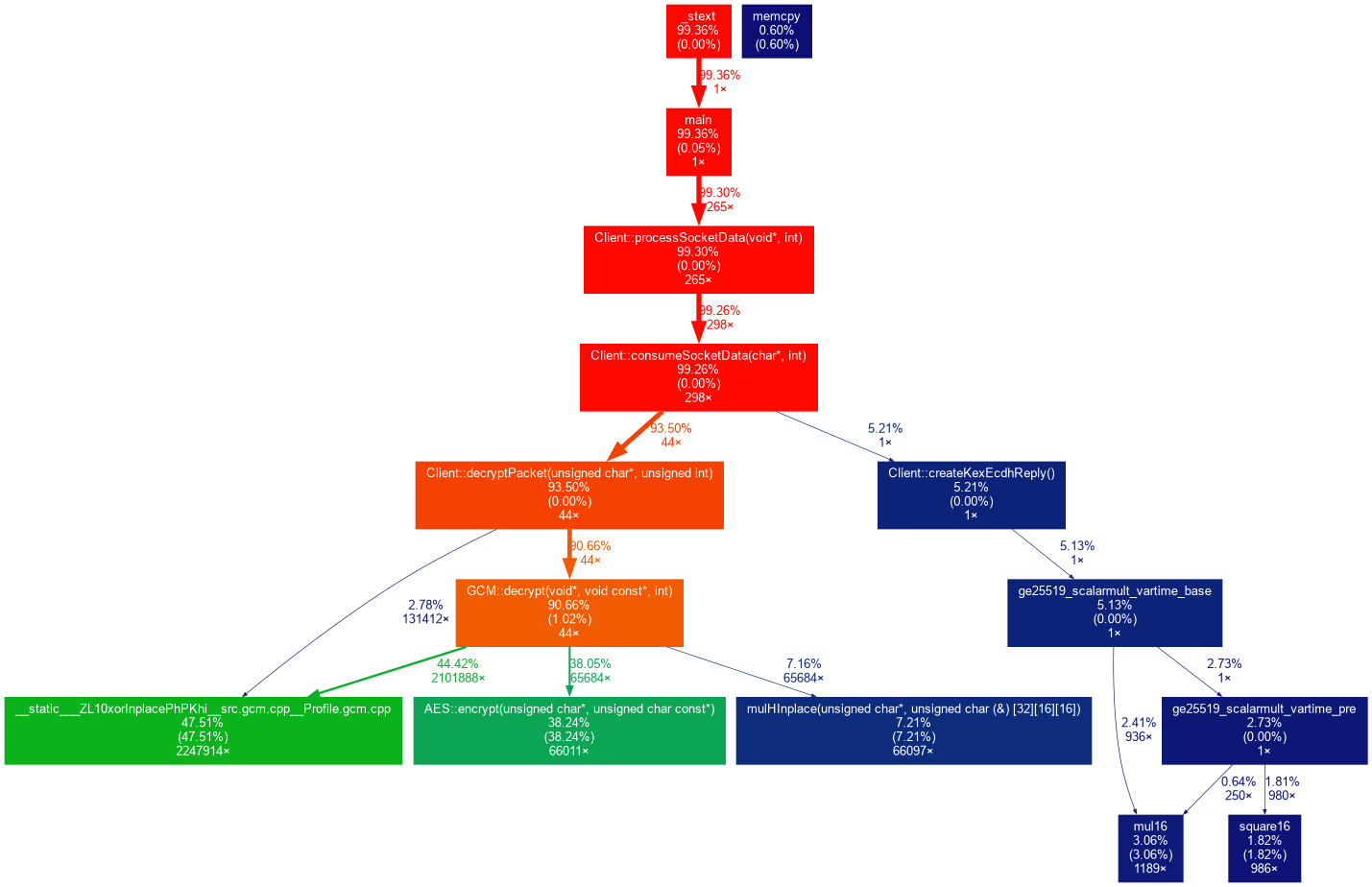
Findings
The GCM/AES encryption is killing it.
Maybe these methods can be improved?
Work in progress
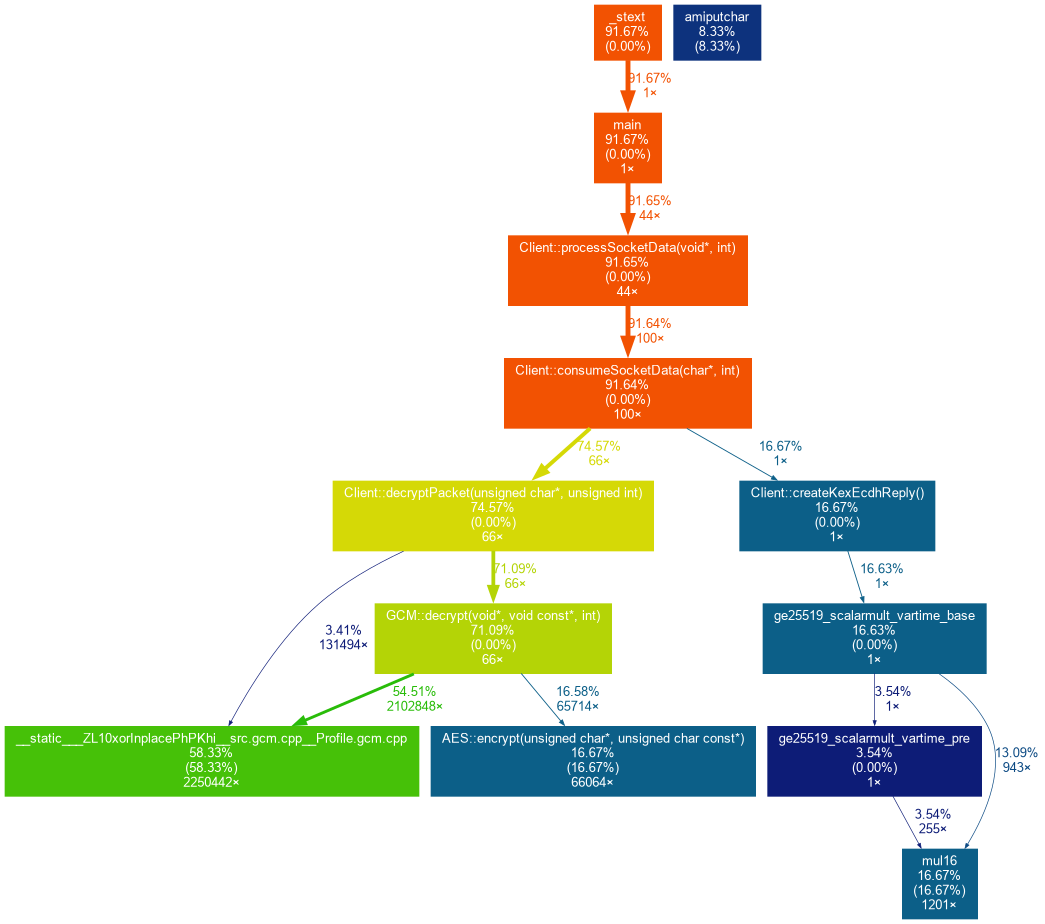
Since the turn around cycle is quicker with WinUAE, I start there to tweak the code. Before:
And improving one of the most used methods, it looks like
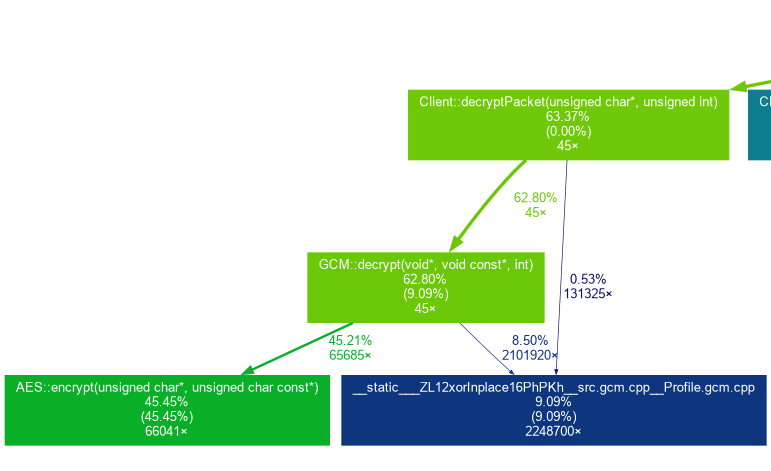
What did I do?
- The code was Java code and there you have to treat bytes as bytes. In C on the Amiga you can xor 4 bytes at once.
=> use 32 bit memory acces where possible
=> The time spent in xorInplace is reduced by ~ factor 4.
- I forced inlining of often called code
=> reduces call overhead
- replaced memcpy for 16 bytes with 4 long moves.
After all the main method's asm looks neat, uses a dbf for the loop.
And the speed gain is there: from 10 kB/s to 20 kB/s on an A3000.
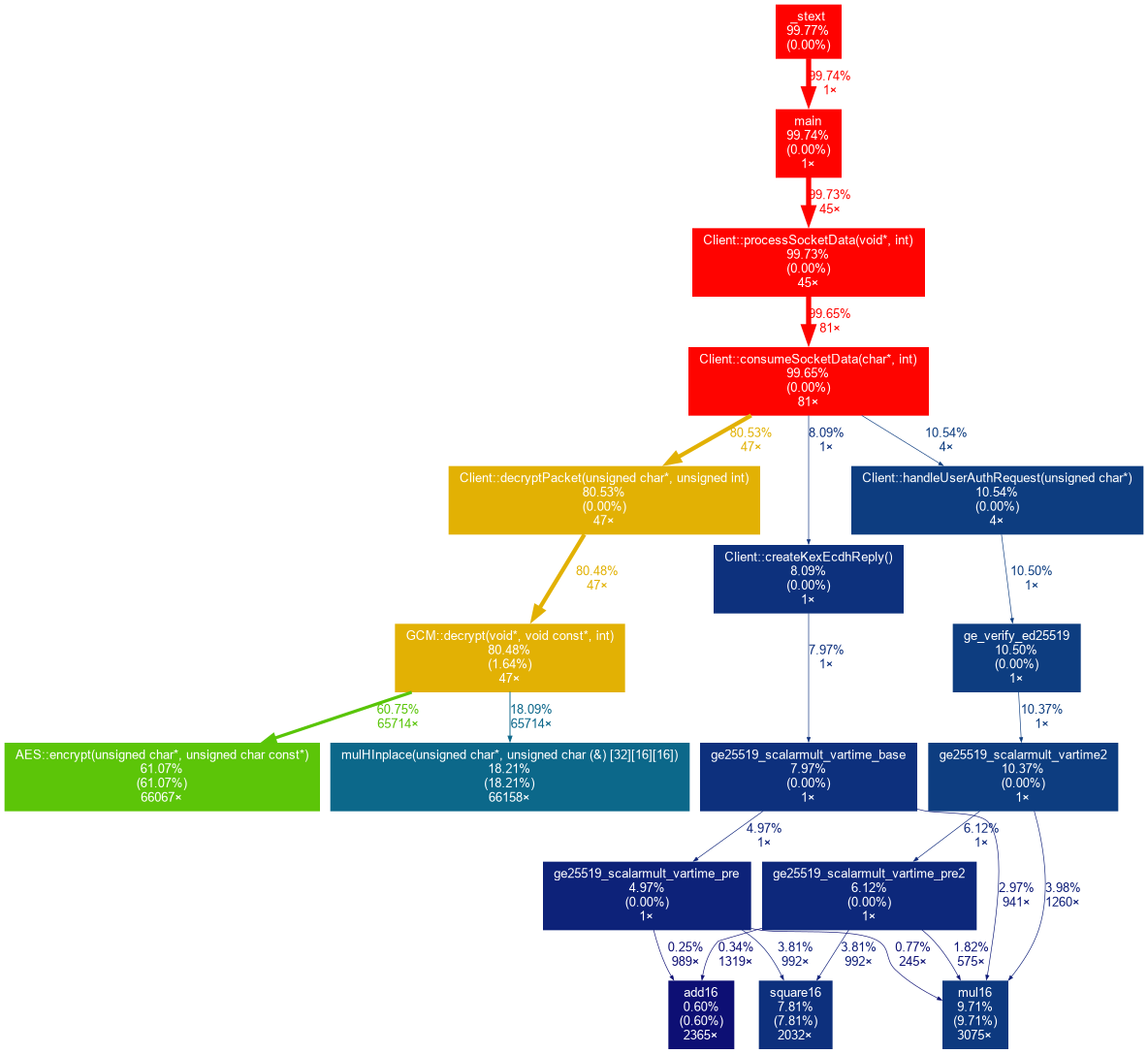
Tipps
Don't use the fastest settings in WinUAE, use cycle exact! This improves the chart.
Here is the chart after improving AES::encyrpt too:
rev: 1.9